









The Valence VWS-173807702 is a mid-tower supporting 1x Intel Xeon W-2400 Series processor and 8x DDR5 memory slots.

-
AI & Deep Learning
Training, building, and deploying Deep Learning and AI models can solve complex problems with less coding. Whether it's data collection, annotation, training, or evaluation, leverage the immense parallelism GPUs offer to parse, train, and evaluate at extremely high throughput. Process massive datasets faster with multi-GPU configurations to develop AI models that surpass any other form of computing.
-
Life Sciences
Training, building, and deploying Deep Learning and AI models can solve complex problems with less coding. Whether it's data collection, annotation, training, or evaluation, leverage the immense parallelism GPUs offer to parse, train, and evaluate at extremely high throughput. Process massive datasets faster with multi-GPU configurations to develop AI models that surpass any other form of computing.
Welcome to the Era of AI
NVIDIA® Tesla® V100 is the most advanced data center GPU ever built to accelerate AI, HPC, and graphics. It’s powered by NVIDIA Volta architecture, comes in 16 and 32GB configurations, and offers the performance of up to 100 CPUs in a single GPU. Data scientists, researchers, and engineers can now spend less time optimizing memory usage and more time designing the next AI breakthrough.

AI Training with Tesla V100
From recognizing speech to training virtual personal assistants and teaching autonomous cars to drive, data scientists are taking on increasingly complex challenges with AI. Solving these kinds of problems requires training deep learning models that are exponentially growing in complexity, in a practical amount of time.
With 640 Tensor Cores, Tesla V100 is the world’s first GPU to break the 100 teraFLOPS (TFLOPS) barrier of deep learning performance. The next generation of NVIDIA NVLink™ connects multiple V100 GPUs at up to 300 GB/s to create the world’s most powerful computing servers. AI models that would consume weeks of computing resources on previous systems can now be trained in a few days. With this dramatic reduction in training time, a whole new world of problems will now be solvable with AI.
AI Inference with Tesla V100
To connect us with the most relevant information, services, and products, hyperscale companies have started to tap into AI. However, keeping up with user demand is a daunting challenge. For example, the world’s largest hyperscale company recently estimated that they would need to double their data center capacity if every user spent just three minutes a day using their speech recognition service.
Tesla V100 is engineered to provide maximum performance in existing hyperscale server racks. With AI at its core, Tesla V100 GPU delivers 47X higher inference performance than a CPU server. This giant leap in throughput and efficiency will make the scale-out of AI services practical.
Tesla V100 Key Features for Deep Learning Training
Deep Learning is solving important scientific, enterprise, and consumer problems that seemed beyond our reach just a few years back. Every major deep learning framework is optimized for NVIDIA GPUs, enabling data scientists and researchers to leverage artificial intelligence for their work. When running deep learning training and inference frameworks, a data center with Tesla V100 GPUs can save up to 85% in server and infrastructure acquisition costs.
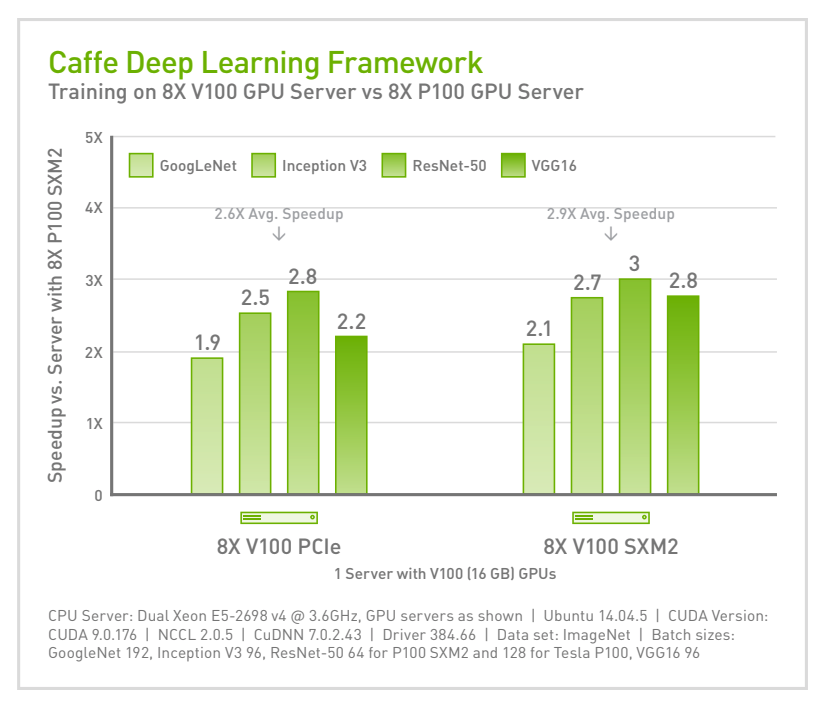
- Caffe, TensorFlow, and CNTK are up to 3x faster with Tesla V100 compared to P100
- 100% of the top deep learning frameworks are GPU-accelerated
- Up to 125 TFLOPS of TensorFlow operations
- Up to 16 GB of memory capacity with up to 900 GB/s memory bandwidth
Accelerating High Performance Computing (HPC) with Tesla V100
To connect us with the most relevant information, services, and products, hyperscale companies have started to tap into AI. However, keeping up with user demand is a daunting challenge. For example, the world’s largest hyperscale company recently estimated that they would need to double their data center capacity if every user spent just three minutes a day using their speech recognition service.
Tesla V100 is engineered to provide maximum performance in existing hyperscale server racks. With AI at its core, Tesla V100 GPU delivers 47X higher inference performance than a CPU server. This giant leap in throughput and efficiency will make the scale-out of AI services practical.
Welcome to the Era of AI
NVIDIA® Tesla® V100 is the most advanced data center GPU ever built to accelerate AI, HPC, and graphics. It’s powered by NVIDIA Volta architecture, comes in 16 and 32GB configurations, and offers the performance of up to 100 CPUs in a single GPU. Data scientists, researchers, and engineers can now spend less time optimizing memory usage and more time designing the next AI breakthrough.
AI Training with Tesla V100
From recognizing speech to training virtual personal assistants and teaching autonomous cars to drive, data scientists are taking on increasingly complex challenges with AI. Solving these kinds of problems requires training deep learning models that are exponentially growing in complexity, in a practical amount of time.
With 640 Tensor Cores, Tesla V100 is the world’s first GPU to break the 100 teraFLOPS (TFLOPS) barrier of deep learning performance. The next generation of NVIDIA NVLink™ connects multiple V100 GPUs at up to 300 GB/s to create the world’s most powerful computing servers. AI models that would consume weeks of computing resources on previous systems can now be trained in a few days. With this dramatic reduction in training time, a whole new world of problems will now be solvable with AI.
AI Inference with Tesla V100
To connect us with the most relevant information, services, and products, hyperscale companies have started to tap into AI. However, keeping up with user demand is a daunting challenge. For example, the world’s largest hyperscale company recently estimated that they would need to double their data center capacity if every user spent just three minutes a day using their speech recognition service.
Tesla V100 is engineered to provide maximum performance in existing hyperscale server racks. With AI at its core, Tesla V100 GPU delivers 47X higher inference performance than a CPU server. This giant leap in throughput and efficiency will make the scale-out of AI services practical.

Tesla V100 Key Features for Deep Learning Training
Deep Learning is solving important scientific, enterprise, and consumer problems that seemed beyond our reach just a few years back. Every major deep learning framework is optimized for NVIDIA GPUs, enabling data scientists and researchers to leverage artificial intelligence for their work. When running deep learning training and inference frameworks, a data center with Tesla V100 GPUs can save up to 85% in server and infrastructure acquisition costs.
- Caffe, TensorFlow, and CNTK are up to 3x faster with Tesla V100 compared to P100
- 100% of the top deep learning frameworks are GPU-accelerated
- Up to 125 TFLOPS of TensorFlow operations
- Up to 16 GB of memory capacity with up to 900 GB/s memory bandwidth
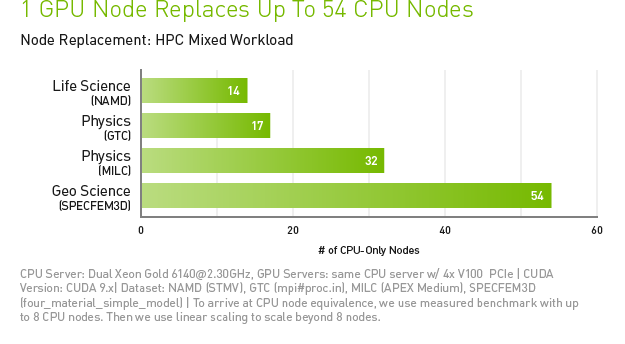
Accelerating High Performance Computing (HPC) with Tesla V100
To connect us with the most relevant information, services, and products, hyperscale companies have started to tap into AI. However, keeping up with user demand is a daunting challenge. For example, the world’s largest hyperscale company recently estimated that they would need to double their data center capacity if every user spent just three minutes a day using their speech recognition service.
Tesla V100 is engineered to provide maximum performance in existing hyperscale server racks. With AI at its core, Tesla V100 GPU delivers 47X higher inference performance than a CPU server. This giant leap in throughput and efficiency will make the scale-out of AI services practical.










Reviews
There are no reviews yet.